本文共 4553 字,大约阅读时间需要 15 分钟。

本文为 AI 研习社编译的技术博客,原标题 :
The Future with Reinforcement Learning — Part 1
作者 | Hunter Heidenreich
翻译 | Disillusion、lyminghaoo
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/the-future-with-reinforcement-learning-part-1-26e09e9be901
强化学习的未来——第一部分
想像这样一个世界:每个计算机系统都根据你的个性而特别定制。它可以学习到你如何与他人沟通,以及你希望他人如何与你沟通的细微差别。与计算机系统的交互将比以往任何时候都更加直接,从而使得科技水平如火箭般推进。在未来强化学习成为常态的情况下,你将可能看到这些结果的出现。
在这篇文章中,我们将对强化学习进行分解,并对强化学习系统的一些组成部分进行剖析。
强化学习高层概述
如果你之前从未听说过强化学习(RL),不要急!这个概念非常直观。从很高的层次上看,强化学习只是:智能体(agent)基于从环境(environment)接收到的反馈信号,学习如何与环境进行交互。 这与其它机器学习方法不同,在那些方法中,智能体可以在训练过程中看到正确答案。但在强化学习中,我们可以认为,我们的智能体只得到了一个让它知道自己的表现如何的分数。
让我们通过一个电子游戏来表达这个思想。假设我们有一个玩“超级玛丽”的电脑程序。它学习控制角色,并通过变化的画面接收来自环境的反馈。基于我们成功(或失败)的算法,它可以学习到如何与环境交互,并利用接收到的反馈来改进。

为了学习所处的环境,我们需要探索!要想知道“板栗仔”(图中怪物)是坏的,而道具是好的,唯一的方法就是通过试错和反馈。
强化学习试图模仿人类或其他智慧生物与新环境交互的方式:试错法。它是在计算机科学、心理学、神经科学、数学等许多领域研究成果的基础上诞生的。虽然强化学习在今天的工业界中并不常见,但它的潜在影响是巨大的。
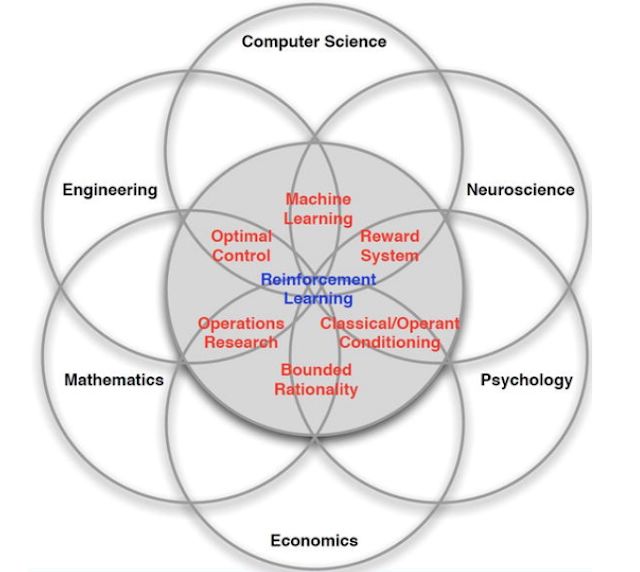
强化学习确实是许多领域的交汇点,它在优化和行为心理学领域有着悠久的历史。
这个潜力,就是我将要为你展示的。
“超级玛丽”游戏中的强化学习词汇
我们已经接触了强化学习玩电子游戏的经典例子。现在,让我们继续使用“超级玛丽”的例子,同时进一步深入挖掘这个概念的思想和相关词汇。
智能体:马里奥
首先,我们有了智能体(agent)。我们的智能体是我们的算法和程序。它是一切操作的“大脑”。它将与我们的环境进行交互。在这个例子中,我们的智能体是马里奥,他会负责所有的控制。

我们的智能体:马里奥
环境:游戏等级
智能体存在于一个环境(environment)的内部。环境就是我们玩的“超级玛丽”的等级。画面中的敌人和方块构成了这个世界。时间在流逝,分数在上升(至少我们希望如此!)。我们的智能体的目标是与环境进行交互,从而获得奖励。

我们的环境:一个简单的等级
动作:跳跃、闪避和前进
什么是奖励?我们的智能体如何获得它?嗯,我们的智能体必须和环境交互。它可以从可选动作列表中选择一个合法的动作来完成交互。可能我们的智能体“马里奥”决定向上跳,或者向左/右移动。也可能有火球道具,所以智能体决定发射一个。关键是,这些动作中的每一个都将影响到环境,并且导致一定的改变。我们的智能体可以观察到这个改变,使用它作为反馈信号,并从中学习到一些东西。

人类可能用这个接口来执行动作并影响环境
状态:马里奥+动作+环境=状态
我们的智能体观察到的改变就是环境状态的改变。智能体观察到的新状态将会产生“奖励”信号。把智能体做的动作、状态的改变、和从状态改变中获得的潜在奖励三者结合起来,智能体就开始为他们要探索的环境建立了一个可行的模型。

状态包含了从我们所观察到的环境中发生的所有信息。比如我们的人物在哪里,我们当前的分数,以及画面中的敌人,所有这些都与我们当前的环境有关。
奖励:分数 + 保持活着
如果智能体学习到,当它跳起并落在敌人上面的时候,它的分数会增加,并且不会再被这个敌人杀死,这一定是一件值得学习的事情!它还可以学到,如果马里奥掉进洞里,游戏就结束了,未来也没有机会获得更多的分数或赢得关卡。这些都是智能体随着时间增加可能学到的东西,与环境的交互越多,它学习到的就越多。

在“超级玛丽”中,一个衡量奖励的好方法可能就是分数了!
上述内容包括了一个强化学习问题中所有主要组成部分的介绍。这个章节中需要记住的重要内容有:智能体、环境、动作、状态和奖励,并尝试在脑中对这些内容进行一个可用的定义。
如果你更习惯看图学习,这张图片很好地把这些概念联系在了一起。
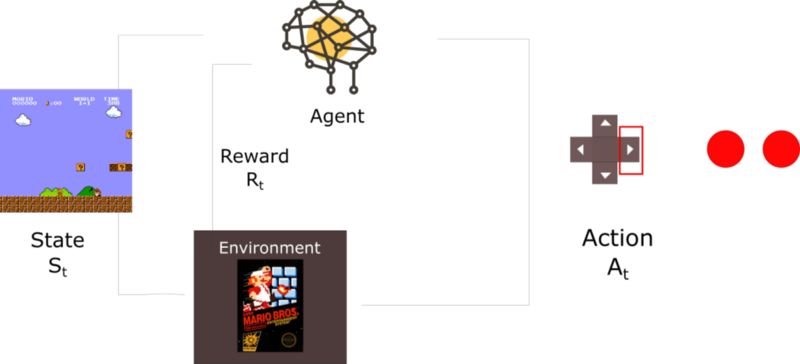
所有部分组合在一起,构成了一个智能体如何从它所处的环境中学习!
它如何工作?
现在我们已经理解了一些基本词汇,我们可以用它去学习一个智能体是如何工作的。一个智能体如何决定它应该做什么动作,来最大化它将会得到的奖励?
我们需要分析理解两个主要的分支:强化学习智能体的需要,以及它的子元素。
强化学习的需要
强化学习智能体必须学习去决策,在一个充满不确定性的环境中什么是一个好的动作。收到的反馈是从观察到的状态变化中得到的延时奖励信号,可以从中计算出奖励。智能体必须能够探索这种不确定性,并对奖励的原因进行推理。要做到这一点,智能体需要有三个简单的东西:动作、目标和感知。
动作
动作是智能体可以在任何给定时刻对环境进行操作的序列。通过执行一个动作,智能体会影响它所处的环境并改变它的状态。如果不能做到这一点,智能体永远不能主动地影响状态,也不能从它的积极或消极地影响环境的行为中获得任何可解释的奖励,甚至不能学会在未来采取更好的动作。
一个人可能对Atari控制器采取的动作序列。
目标
目标指我们如何定义奖励信号。我们是否要根据游戏中的分数定义奖励?还是完成一个关卡?什么是好的和坏的动作?在强化学习的背景下定义目标时,我们必须考虑这些问题。这关乎我们如何激励智能体完成一项任务。
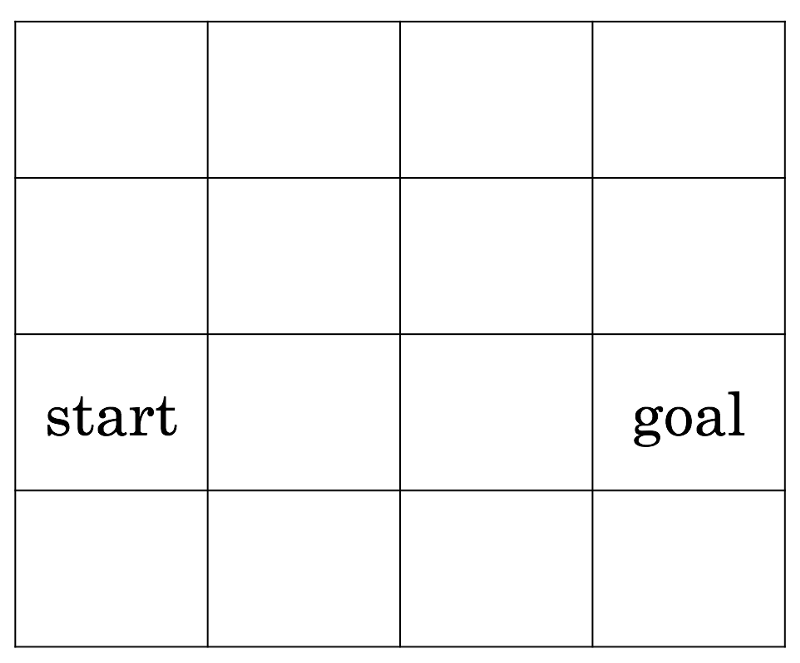
一个简单的目标设定。一个人该怎么从开始到结尾?
感知
智能体用感知来观察环境。在电子游戏环境中,也许可以使用计算机视觉技术来观察屏幕上的对象,以及当我们的智能体做出动作时,这些对象是如何变化的。也许我们可以用光学字符识别(OCR)技术来观察分数。关键是,如果智能体不能感知环境,就不能推断它的动作如何影响了环境。因此,我们需要感知来监控我们交互的环境。
强化学习系统的子元素
现在,我们可以转换到RL系统的子元素:策略、奖励信号、值函数和环境最优模型。
策略
策略是我们RL智能体的核心。这是我们的智能体在给定环境当前状态下的行为方式。以及在给定状态下所采取的行动。在生物学中,我们可能把策略看作一个有机体如何根据它所受到的刺激做出反应。我们的智能体观察环境的状态,策略就是它们学到的行动。好的策略会带来积极的结果。
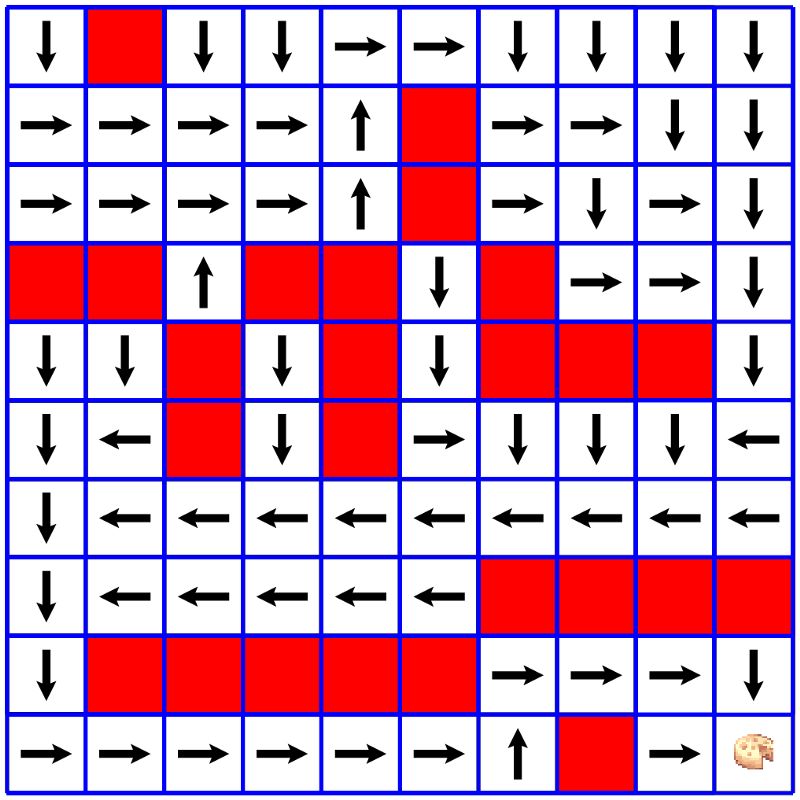
我们的策略将规定在给定环境状态下智能体将做什么。我们可以看到在这策略是给定一个格子,我们的智能体将朝某个方向移动。
奖励信号
奖励信号指我们如何衡量智能体的成功。它是衡量我们在实现目标方面有多成功的数字指标。奖励信号可以是积极的或消极的,这样我们的智能体就可以判断一个行为是好是坏,亦或是中性的。这些可以是视频游戏中的分数,或是智能体的存活状况。关键是,我们的智能体接收这些奖励信号,衡量当前目标的完成表现如何,并基于这些反馈来制定其策略,以便它可以进一步改变环境,从而最大化未来可能获得的奖励。
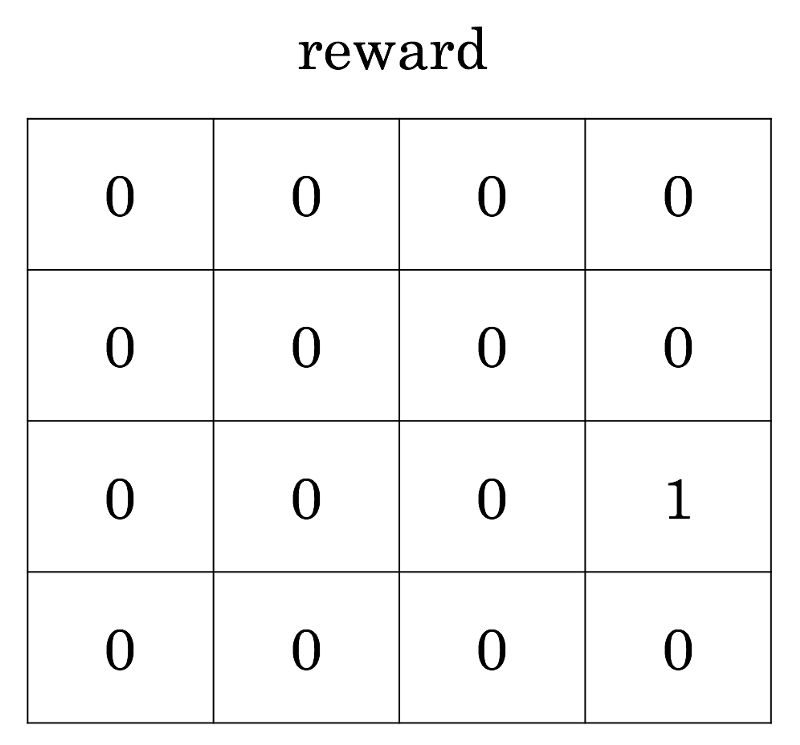
我们可以把它看作是之前目标图像中隐藏奖励的映射。只有通过探索环境,智能体才能知道踩在目标格子上得到的奖励是1!
值函数
我们可以把奖励信号看作是判断一个行为是好是坏的即时指标。然而,强化学习不仅仅是关于即时的正面或负面结果。而是通过长期的计划来最好地完成一项任务。为了对这种长期性能建模,我们引入了一个称为值函数的概念。值函数是对我们的智能体长期成功可能性的估计。这很难估计和测量的,但它是我们RL问题最关键的部件之一!在不确定的环境中,我们的智能体将在多次迭代中不断修改其对值的估计,学习如何更好地塑造策略和行为,以接管长序列的行为和状态。
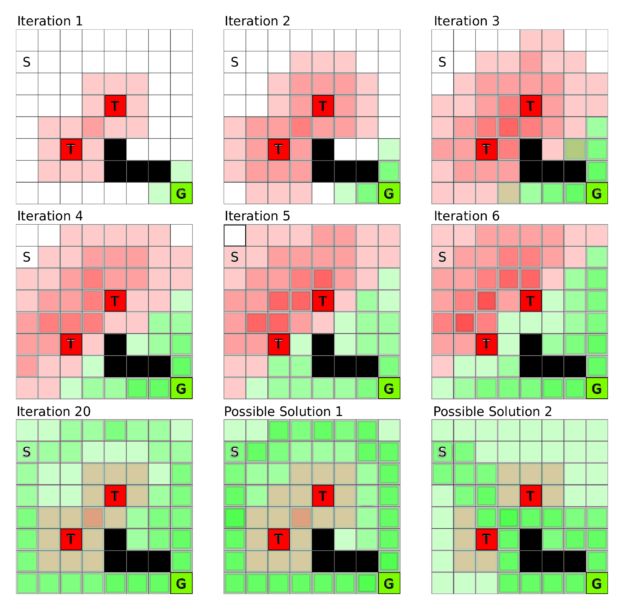
由智能体形成的值函数的可视化。当它对自己所处的状态下可能得到的长期奖励越来越确定时,它就能想出应对这一挑战的办法。
环境的最优模型
最后,我们的强化学习系统可能要为环境建模。我之所以说“可能”,是因为并非所有强化学习智能体都会为环境建模。一些智能体只是简单地通过反复试错来学习,通过好的评价函数和策略组合来构建一定程度上隐式的环境模型。其它智能体可以显式地创建环境的内部模型,允许智能体根据它希望直接执行的动作,来预测结果状态和奖励。这似乎是一种非常好的方法,但是在高度复杂的环境中,构建这样的内部模型是极其困难的,所以智能体通常不会选择这种策略。
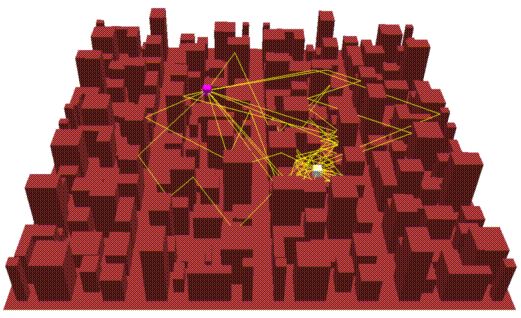
当智能体探索一个环境时,它可以构建一个周围世界的3D解释,以帮助它推断未来可能执行的动作。
总结
有了这些基本概念,我们就可以开始展望未来了,计算机系统将根据我们的行为和反应来学习,并根据我们的个性进行调整。如同我们上面例子中的智能体“马里奥”,我们可以设想未来的计算机系统能够读取我们的行为和反应,就像人物“马里奥”读取环境一样。当它让我们越高兴,以及让我们越快实现我们的目标时,它会得到更多的奖励。很容易看出,这种未来的结果可能是在我们的能力范围内的。
即将到来:第二和第三部分
所有这些加在一起,使我们对强化(学习)系统如何运作有了一个基本的概念。这个高层的基础将对我们文章的第二部分有所帮助,我们将讨论如何强化学习与其他类型机器学习的比较,以及我们认为在形式化一个强化学习问题时的一些(关键的)因素。文章的第三部分中,我们将看到一些强化学习领域最近的成就和开放的研究问题。
观看动态的“超级玛丽”游戏!看看你能否识别出强化学习场景中需要的所有元素。(请在英文栏点击链接)
MarI/O - Machine Learning for Video Games
https://youtu.be/qv6UVOQ0F44
如果你喜欢阅读这篇文章,请给我留言,或者向我的 GoFundMe 捐款,帮助我继续我的机器学习研究!
最初于 2018 年 8 月 8 日发表在 recast.ai 上。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【强化学习的未来--第一部分】:
https://ai.yanxishe.com/page/TextTranslation/1369
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网雷锋网雷锋网(公众号:雷锋网)
自然语言处理中的词表征(第一部分)
自然语言处理中的词表征(第二部分)
图片语义分割深度学习算法要点回顾
特朗普都被玩坏了,用一张照片就能做出惟妙惟肖的 Memoji
等你来译:
强化学习的未来——第一部分
初学者怎样使用Keras进行迁移学习
强化学习:通往基于情感的行为系统
如果你想学数据科学,这 7 类资源千万不能错过
转载地址:http://pwtkx.baihongyu.com/